O câncer de mama é o segundo tipo de câncer mais frequente no mundo e o primeiro entre as mulheres. Os melhores exames para diagnóstico prematuro deste tipo de câncer são primeiramente a mamografia e depois o autoexame. O presente trabalho tem como objetivo propor uma metodologia que, usando técnicas de processamento digital de imagens, possa auxiliar no diagnóstico desses tumores em imagens de mamografias.
A metodologia proposta consiste na aplicação de filtros, modificações de contraste e realização de sucessivas decomposições de uma imagem mamográfica de forma a permitir uma melhor visualização e localização de possíveis tumores. Espera-se que este processamento permita que possíveis nódulos de câncer no mamografia sejam ressaltados, auxiliando o médico a realizar um diagnóstico mais preciso e rápido, possibilitando um melhor prognóstico ao paciente e encaminhamento ao
tratamento adequado. A metodologia proposta mostra-se promissora considerando os resultados obtidos, quais sejam sensibilidade e especificidade de 86% e 75%,
respectivamente, e 84% de eficiência na detecção dos tumores.
O TensorFlow é uma tecnologia que pode ser utilizado no diagnóstico de mamografia por meio da aplicação de técnicas de aprendizado de máquina e redes neurais convulsionais (CNNs), com avaliação de banco de dados, contribui para uma melhor eficiência de detecção de tumores, de forma mais rápida e pratica.

Aqui está um exemplo de como o TensorFlow pode ser empregado nesse contexto:
- Pré-processamento de Imagens: Antes de alimentar as imagens de mamografia em um modelo de TensorFlow, é importante pré-processá-las. Isso pode envolver redimensionamento, normalização, aumento de dados (data augmentation) e outras técnicas para melhorar a qualidade e a robustez do modelo.
- Construção do Modelo CNN: O TensorFlow fornece uma variedade de ferramentas para construir modelos de CNN. Você pode usar a API de alto nível, como o Keras, que é integrado ao TensorFlow, para construir e treinar modelos de forma rápida e eficiente.
- Treinamento do Modelo: O treinamento do modelo de CNN envolve alimentar as imagens de mamografia pré-processadas ao modelo e ajustar os pesos das redes neurais de acordo com os rótulos correspondentes (por exemplo, se uma imagem contém um tumor maligno ou benigno). Durante o treinamento, o modelo tentará minimizar uma função de perda (loss function) através de algoritmos de otimização, como o gradiente descendente.
- Validação e Avaliação do Modelo: Após o treinamento, é importante validar o modelo em um conjunto de dados de validação para verificar se ele generaliza bem para novos dados. Além disso, é essencial avaliar o desempenho do modelo em um conjunto de dados de teste separado para medir sua precisão, sensibilidade, especificidade e outras métricas relevantes para o diagnóstico de mamografia.
- Interpretação dos Resultados: Uma vez treinado e avaliado, o modelo pode ser utilizado para fazer previsões em novas imagens de mamografia. No entanto, é fundamental interpretar os resultados com cuidado e considerar os aspectos clínicos e contextuais antes de tomar decisões médicas.



Rede neural artificial
Antes da aprendizagem profunda, rede neural era somente uma entre muitas técnicas de aprendizagem. Porém, agora ela é a técnica de aprendizagem mais importante, pois é a base para a aprendizagem profunda. Rede neural também consegue resolver o problema ABC, mas o seu mecanismo de funcionamento é mais complexo que o “vizinho mais próximo”.
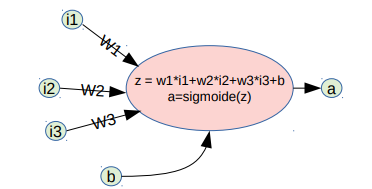
Um neurônio da rede (Figura Abaixo) recebe n entradas i1, …, in (isto é, n números), multiplica-as pelosrespectivos pesos wi, soma um viés b, aplica uma função de ativação ao resultado para gerar a saída a(um número)

Um neurônio da rede neural artificial.
Uma rede neural consiste de vários neurônios interconectados. A rede neural que resolve o problema ABC está na (Figura Abaixo) . Cada “flecha” da rede possui um peso associado e cada neurônio da rede possui um viés associado. Para simplificar, vou chamar de “pesos” o conjunto formado pelos os pesos mais o vieses. O problema é encontrar os pesos que classifiquem corretamente os indivíduos em A, B ou C.

Estrutura da rede neural para resolver problema “Adulto”, “Bebê” e “Criança”.
Para usar rede neural, vamos converter os rótulos A, B e C em vetores (1, 0, 0), (0, 1, 0) e (0, 0, 1), pois a rede da (Figura Acima) possui três saídas (Tabelas Abaixo). Precisamos encontrar os pesos que fazem a classificação desejada. Para isso, o programa inicializa aleatoriamente os pesos. Para treinar a rede, o programa apresenta à rede um exemplo de treinamento (por exemplo “4”) e pega a saída fornecida pela rede. A saída desejada é o vetor (0, 1, 0) significando “Bebê”. Então, o programa modifica um pouquinho cada peso para que a saída obtida fique um pouco mais próxima da desejada.

Amostras de treinamento e vetor de categorias

Instâncias de teste e vetor de categorias.
É como mexer um pouco a bolinha da (Figura Abaixo) de lugar para que ela vá para um ponto com erro um pouco mais baixo. Este processo, chamado de retro-propagação, é repetido muitas vezes para todos os exemplos de treino. Após o treino, a rede aprende a classificar corretamente os indivíduos.

Retro-propagação muda os valores dos pesos para chegar ao ponto de baixo erro.
Aprendizagem de máquina supervisionada (ou inteligência artificial)
“Aprendizagem de máquina” é uma sub-área de “inteligência artificial”. “Aprendizagem profunda” éuma sub-área de “aprendizagem de máquina”. Porém, muitas vezes os três termos são usados como sinônimos.
Aprendizagem de máquina supervisionada é, em essêcia, algo muito simples. Considere o problema de classificar um indivíduo em “Adulto”, “Bebê” ou “Criança” (ABC), dado o seu peso em kg. Para isso, o usuário fornece ao computador a tabela 1, com exemplos de entrada-saída. Por exemplo, a primeira linha (4, B) indica que a classificação de um indivíduo de 4 kg é “Bebê”.
Depois, o usuário pede ao computador que classifique o indivíduo com característica “16” (tabela 2). O computador pode adotar diferentes técnicas para classificar “16”, mas uma ideia razoável é procurar, entre os exemplos de treino, aquela instância mais parecida a “16”. Fazendo isto, computador encontra característica “15” cuja classificação é “C”. Então, o computador acredita que o indivíduo “16” deve ser da mesma categoria que “15” e atribui rótulo “C” a “16”. Este método chama-se “vizinho mais próximo”.


Evidentemente, este problema é simples demais. Um exemplo um pouco mais complexo está ilustrado na figura 1. Dadas duas características de um inseto (por exemplo, seu comprimento e peso), classificá-lo em “grilo”, “gafanhoto” ou “formiga”. Aqui também “vizinho mais próximo” pode ser usado.
Existem muitos outros algoritmos de aprendizagem além do “vizinho mais próximo”: árvore de decisão, boosting, classificador de Bayes, support vector machine, rede neural artificial, etc. Todos eles resolvem bem os problemas simples como os acima.
O problema é que uma mamografia não possui 1, 2 ou 3 características de entrada. Possui tipicamente 3000×4000=12.000.000 pixels e nenhum algoritmo de aprendizagem convencional funciona bem com esta quantidade de entradas.

Classificação do inseto em grilo, gafanhoto ou formiga usando duas características.
Referência:
curated_breast_imaging_ddsm,curated_breast_imaging_ddsm | TensorFlow Datasets
Deixe um comentário